When you perform a Reconfigure for vSphere HA operation on the primary node in an HA cluster, an unexpected virtual machine failover may occur for the virtual machines running on that primary node. This is caused by a too short default monitor period for the primary host to become secondary. In the Details tab you can see the potentially affected clusters. Click the Ask VMware link above for more details and a resolution
Had the following error in skyline:
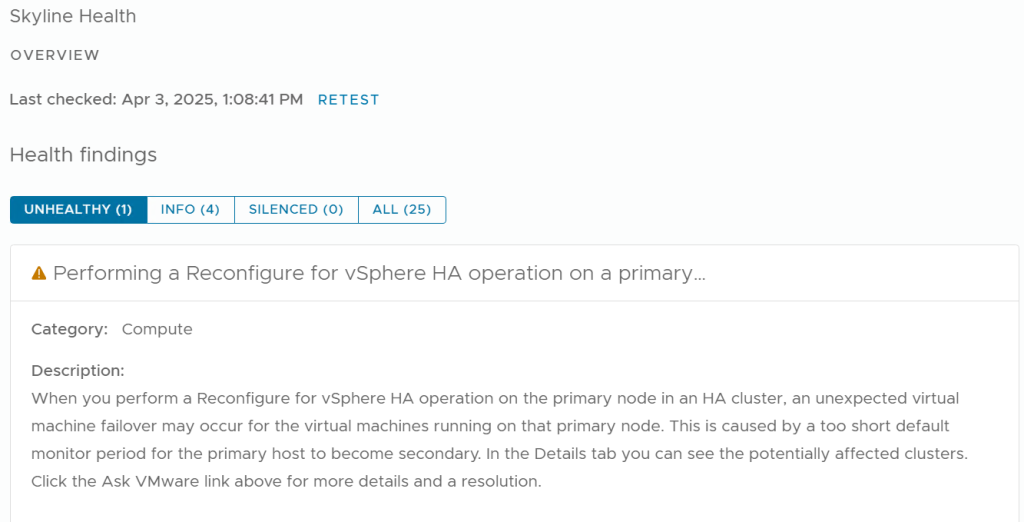
Needed to add this setting into the advanced HA settings:
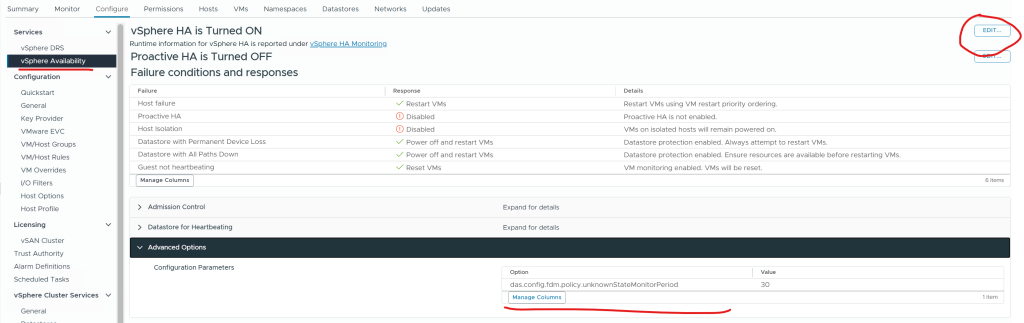
das.config.fdm.policy.unknownStateMonitorPeriod 30this won’t work for vSphere 8.0U2 and above: das.config.fdm.unknownStateMonitorPeriod 30. This was the reason i was getting an alert!
More information can be found here: https://knowledge.broadcom.com/external/article?legacyId=2017778
The option can be set here at the cluster level:
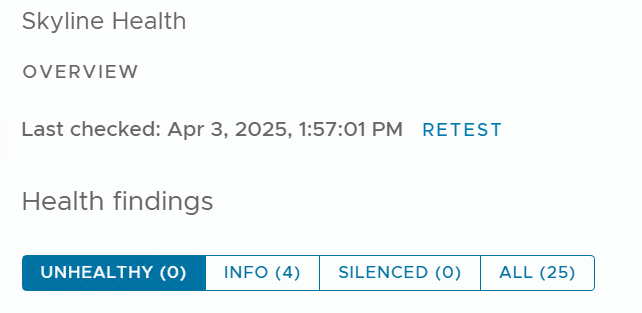
Retested Skyline and that fixed my issue:
Leave a Reply